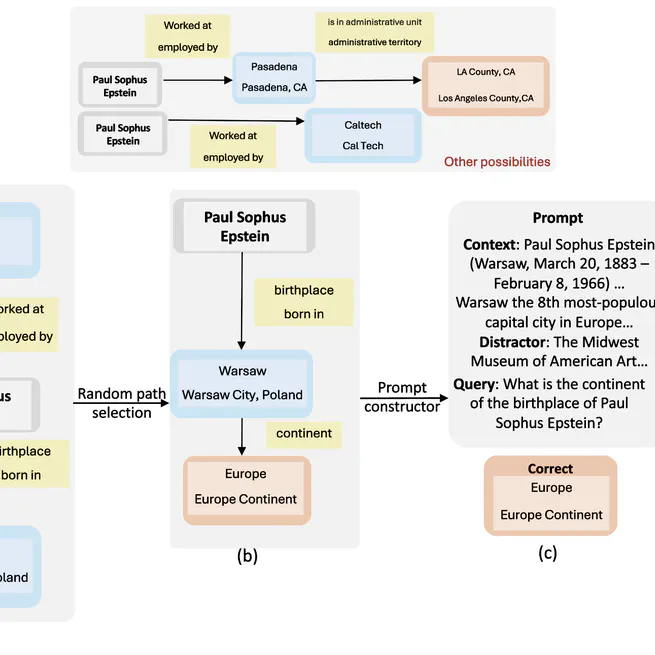
Quacer-C- Quantitative Certification of Knowledge Comprehension in LLMs
QuaCer-C is a framework for quantitatively certifying the knowledge comprehension capabilities of Large Language Models (LLMs). Using the structured nature of knowledge graphs, we are able to derive specifications for reasoning over unstructured data like text providing a way to formally understanding reasoning using exact confidence intervals. Authors: Isha Chaudhary, Vedaant Jain, Gagandeep Singh
Sep 10, 2024

HumorDB
HumorDB is a novel image-only dataset designed to advance visual humor understanding in AI systems. It consists of carefully curated image pairs with contrasting humor ratings, emphasizing subtle visual cues that trigger humor while mitigating potential biases. The dataset enables evaluation through binary classification, range regression, and pairwise comparison tasks. Authors: Vedaant Jain, Felipe Feitosa, Gabriel Kreiman
Jun 12, 2024
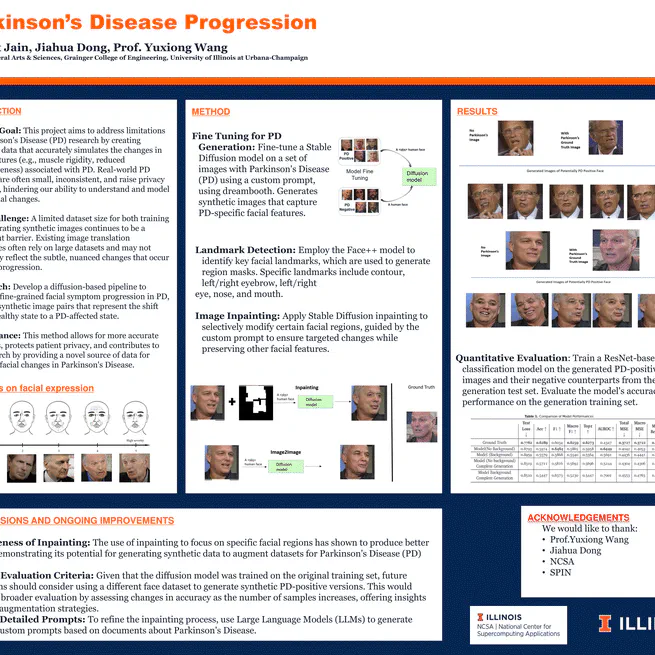
Parkinson's Disease Progression
This project addresses limitations in Parkinson’s Disease (PD) research by creating synthetic data that aims to simulate changes in facial features associated with PD progression. Using diffusion models and inpainting techniques, we developed a pipeline to generate realistic image pairs representing the transition from healthy to PD-affected facial states. Additionally, we utilized evaluations based on training classification models on the synthetic data. We also explored Model generalization using subset of FFHQ dataset and saw improvement by 5% over previous model baseline.
May 12, 2024
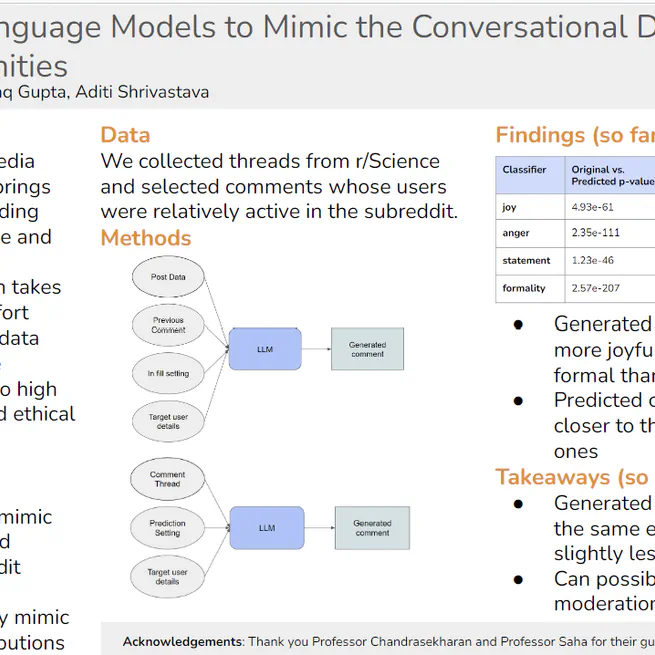
LLMs Mimic Reddit
This project explores the potential of Large Language Models (LLMs) to accurately simulate user behavior in Reddit communities. We investigate if LLMs can effectively mimic the communication patterns of specific users when provided with their comment history as context, focusing on the r/science subreddit. Authors: Vedaant Jain*, Yoshee Jain∗, Ishq Gupta, Aditi Shrivastava, Koustuv Saha, Eshwar Chandrasekharan
May 10, 2024
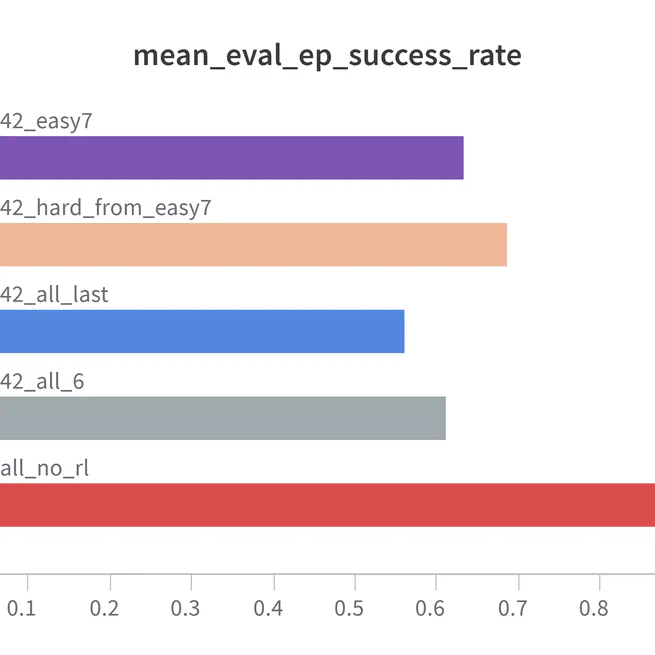
Curriculum Learning for Embodied Planning with LLMs
This project explores the application of Curriculum Learning to improve the performance of GPT-2 models in Embodied Natural Language Processing tasks using the ALFWorld dataset. We developed curricula for both Action Modeling and Reinforcement Learning stages, demonstrating significant improvements in task success rates and action efficiency. Authors: Bohan Liu, Vedaant Jain, Aarohi Gupta
May 10, 2024
Multi-Modal Information Extraction from Academic Resumes
This project addresses the challenge of extracting structured information from academic resumes, which often span multiple pages and contain complex, domain-specific content. We developed a novel approach combining document layout analysis and sequence tagging to accurately segment and extract key information from various resume sections.
May 10, 2023
Neural Style Transfer with Rust and PyTorch
This project implements artistic style transfer using Convolutional Neural Networks (CNNs) in Rust. It combines the content of one image with the artistic style of another, creating unique visual outputs. The system is deployed as a web application, allowing users to easily interact with the model through a REST API.
Dec 10, 2022